For additional background on Brick, be sure to check out the reading list
This document attempts a brief summary of “point mapping” techniques and technologies, with a particular emphasis on mapping point labels from a building management system (BMS) into a Brick model.
What are Point Labels?
BMS points are the I/O elements for a building For a good primer on BMS points see this article . They are the identifiers used by software to read data from the building (e.g. sensor values) and to write data to the building (e.g. changing setpoints). Points are given labels in the BMS – think of these like variable names used by software to perform the read/write actions. These labels are largely ad-hoc constructions driven by vendor- or site-specific conventions.
One of my favorite examples is SODA1R465_ARS, which is a real point name from Soda Hall
on the UC Berkeley campus. The following slide screenshot illustrates how this label
is properly broken down into its components:
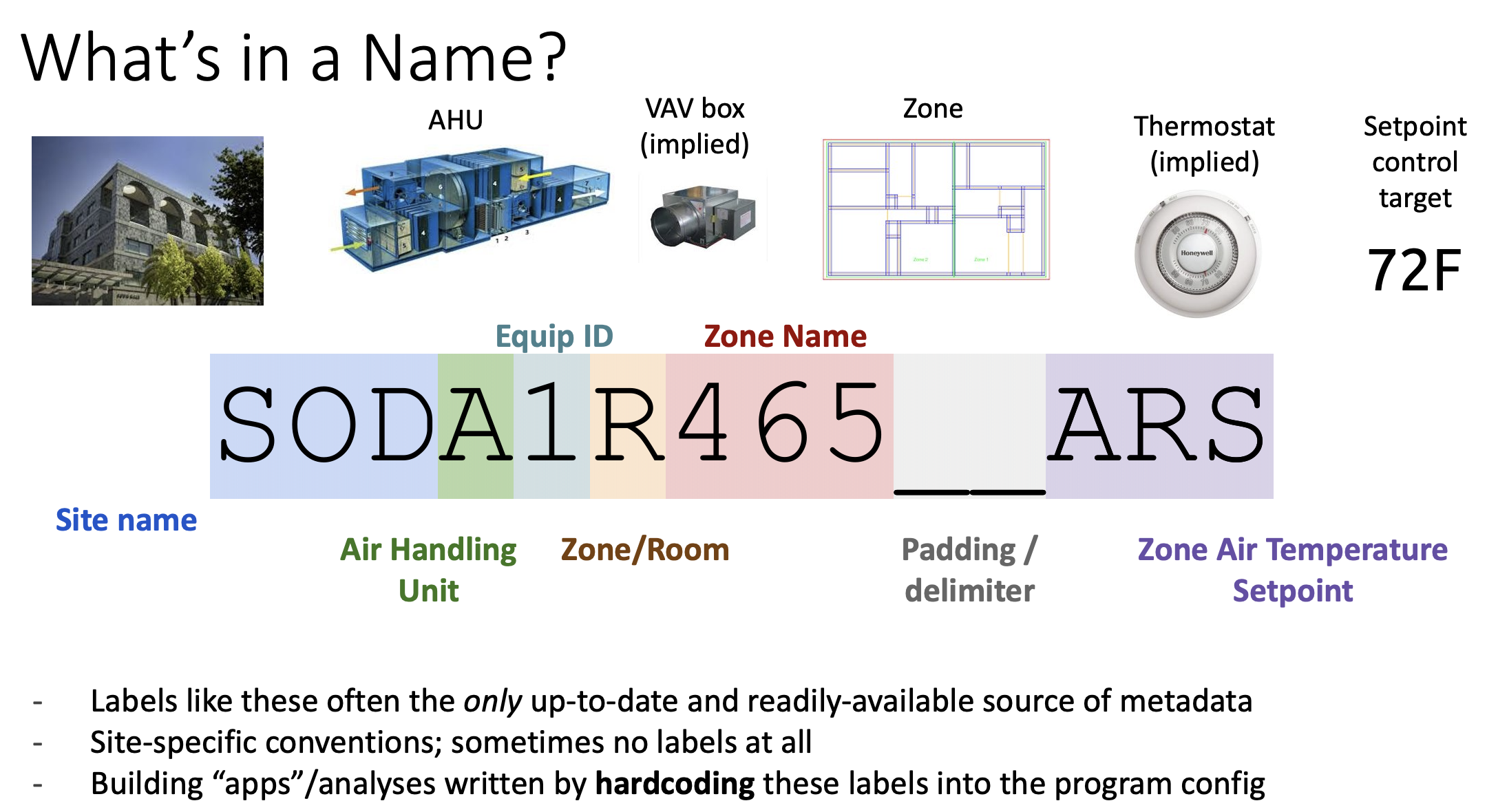
As you can see, the label contains semi-structured information that implies elements of the building’s structure. The role of a Brick model is, in part, to make this structure explicit and encode it in a standard way that is accessible to software.
The Brick model for the point above might look something like this:
@prefix brick: <https://brickschema.org/schema/Brick#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix campus: <urn:campus/> .
campus:SodaHall a brick:Building ;
rdfs:label "SOD" ; # pulled from the label
brick:isLocationOf campus:SOD_A1 .
campus:SOD_A1 a brick:Air_Handling_Unit ;
rdfs:label "SODA1" ;
brick:feeds campus:SOD_A1_R465 .
campus:SOD_A1_R465 a brick:HVAC_Zone ;
rdfs:label "SODA1R465" ;
brick:hasPoint campus:SOD_A1_R465_ARS .
campus:SOD_A1_R465_ARS a brick:Room_Air_Temperature_Setpoint ;
rdfs:label "SODA1R465__ARS" .
For clarity, I am associating each entity with the portion of the point label used to construct it. I am also leaving out the implied information from the figure above.
The Briefest Point Mapping Survey
Point mapping is the process of converting point labels like
SODA1R465__ARS into RDF graphs that make the internal structure of the label
explicit. There are several ways of approaching this, presented in order from
most human-intensive to least human-intensive:
-
Human-driven data cleaning: this body of techniques sees human operators performing the parsing of labels using data cleaning software into some structured (typically tabular) representation. This structured representation can be used with templating tools (like Brickify, brick-builder, or BuildingMOTIF)
OpenRefine is a great tool for doing this parsing in an automated way. I have a YouTube tutorial video on using OpenRefine to parse point labels and generate a Brick model.
-
Active learning and automated parsing: these are techniques that use human experts (often per-site experts) to teach a program how to parse a label into its components. These techniques reduce human effort by identifying and prioritizing common point structures.
Dr. Bhattacharya’s work pioneered this approach, which is continued in his Phd dissertation (see chapter 3). Dr. Koh continued this work by using existing natural language processing parsing techniques. Some of this work (Plaster) was released as an open source package, and there is further detail in his PhD dissertation
-
Fully-automated mapping: this last set encapsulates techniques that eliminate or obviate human input from the point mapping process. There is little work in this area, but Waterworth et al have proposed the use of large language models for point mapping.
Key Components of Point Mapping
When designing software to manage or perform point mapping, it is important to consider the key components of the process. Point mapping has human-assisted and machine-assisted components. The UX should center the human-assisted components and abstract away managing the machine-assisted components. Exactly what the human/machine components are depends on the approach to point mapping.
Consider the example of human-driven data cleaning. The UX should focus on point label parsing and assignment of the parsed data into some graph structure. This will likely include assigning classes to identified components of the parsed label. One might suggest classes based on heuristics over the point label